
scrapy 爬虫框架 入门
scrapy介绍
scrapy 是 python3 下面的一个爬虫框架(spider)
安装
pip install scrapy
截止于2019/03/02,最新版本是1.6
简单样例(非工程)
这个样例是非项目样例,这个样例用于快速入门和体验,只有爬虫脚本,没有中间件、管道和配置文件。
# $ pip install scrapy
# $ cat > myspider.py <<EOF
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://blog.scrapinghub.com']
def parse(self, response):
for title in response.css('.post-header>h2'):
yield {'title': title.css('a ::text').get()}
for next_page in response.css('div.prev-post > a'):
yield response.follow(next_page, self.parse)EOF
# $ scrapy runspider myspider.py
你可以直接把这个spider往Scrapy Cloud上部署。
部署流程如下
$ pip install shub
$ shub login
Insert your Scrapinghub API Key: <API_KEY>
# Deploy the spider to Scrapy Cloud
$ shub deploy
# Schedule the spider for execution
$ shub schedule blogspider
Spider blogspider scheduled, watch it running here:
https://app.scrapinghub.com/p/26731/job/1/8
# Retrieve the scraped data
$ shub items 26731/1/8
{"title": "Improved Frontera: Web Crawling at Scale with Python 3 Support"}{"title": "How to Crawl the Web Politely with Scrapy"}...
scrapy 项目入门
scrapy 架构初步讲解
-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
-
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
-
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
-
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
-
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
-
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
-
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
架构图

处理时序图
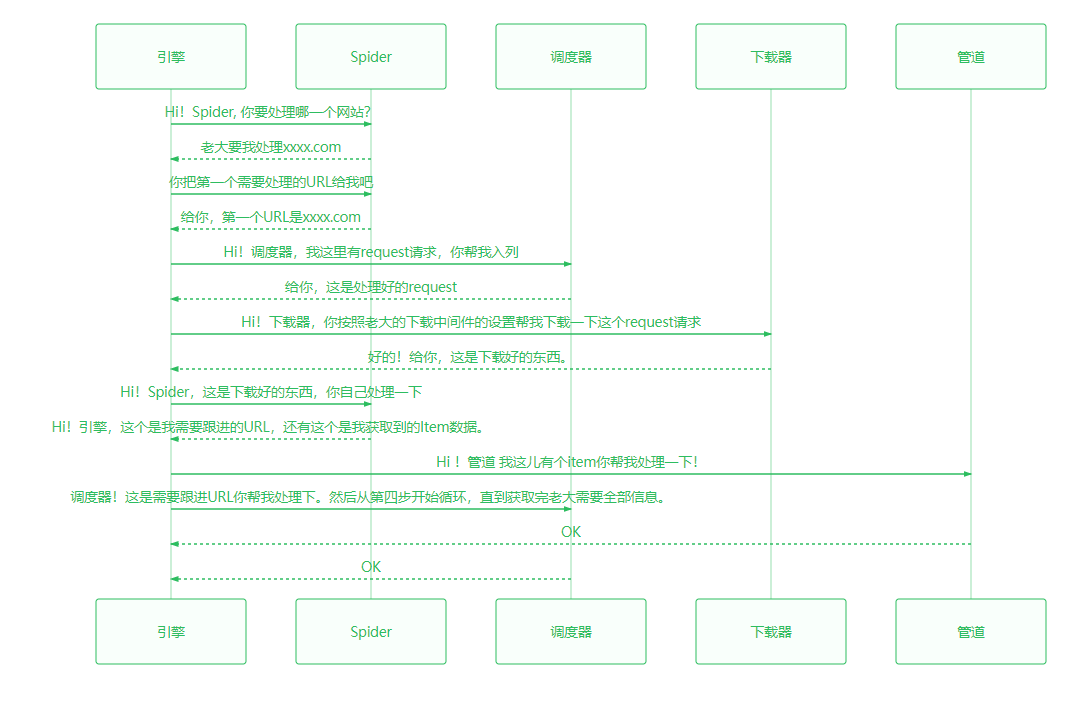
sequenceDiagram
引擎->>Spider: Hi!Spider, 你要处理哪一个网站?
Spider-->>引擎: 老大要我处理xxxx.com
引擎->>Spider:你把第一个需要处理的URL给我吧
Spider-->>引擎:给你,第一个URL是xxxx.com
引擎->>调度器:Hi!调度器,我这里有request请求,你帮我入列
调度器-->>引擎:给你,这是处理好的request
引擎->>下载器:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
下载器-->>引擎:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
引擎->>Spider:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
Spider-->>引擎:Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
引擎->>管道:Hi !管道 我这儿有个item你帮我处理一下!
引擎->>调度器:调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
管道-->>引擎:OK
调度器-->>引擎:OK
制作爬虫的步骤
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
创建一个项目
1.新建项目
$ scrapy startproject spider_demo
这样会创建一个spider_demo文件夹,这个文件夹的结构如下:
spider_demo/
scrapy.cfg # deploy configuration file 配置文件
spider_demo/ # project's Python module, you'll import your code from here 项目文件夹
__init__.py
items.py # project items definition file items定义文件
middlewares.py # project middlewares file 中间件文件
pipelines.py # project pipelines file 管道文件
settings.py # project settings file 项目设置文件
spiders/ # a directory where you'll later put your spiders 爬虫文件夹(爬虫放这里哦)
__init__.py
2.编写目标
例如:我们要抓取豆瓣电影里面的电影的名称、介绍、星级、评论数、描述等信息。
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序号
num = scrapy.Field()
# 电影的名字
name = scrapy.Field()
# 电影的介绍
intro = scrapy.Field()
# 电影的星级
star = scrapy.Field()
# 电影的评论数
eval = scrapy.Field()
# 电影的描述
desc = scrapy.Field()
3.制作爬虫
在spider目录里面新建一个spider文件,继承 scrapy.Spider
import scrapy
class mySpider(scrapy.Spider):
# 以下是爬虫程序
4.保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下: json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
xml格式
scrapy crawl itcast -o teachers.xml
